ObjectGoal Navigation (ObjectNav) is an embodied task wherein agents are to navigate to an object instance in an unseen environment. Prior works have shown that end-to-end ObjectNav agents that use vanilla visual and recurrent modules, e.g. a CNN+RNN, perform poorly due to overfitting and sample inefficiency. This has motivated current state-of-the-art methods to mix analytic and learned components and operate on explicit spatial maps of the environment. We instead re-enable a generic learned agent by adding auxiliary learning tasks and an exploration reward. Our agents achieve 24.5% success and 8.1% SPL, a 37% and 8% relative improvement over prior state-of-the-art (Chaplot et al 2020), respectively, on the Habitat ObjectNav Challenge. From our analysis, we propose that agents will act to simplify their visual inputs so as to smooth their RNN dynamics, and that auxiliary tasks reduce overfitting by minimizing effective RNN dimensionality; i.e. a performant ObjectNav agent that must maintain coherent plans over long horizons does so by learning smooth, low-dimensional recurrent dynamics.
Approach
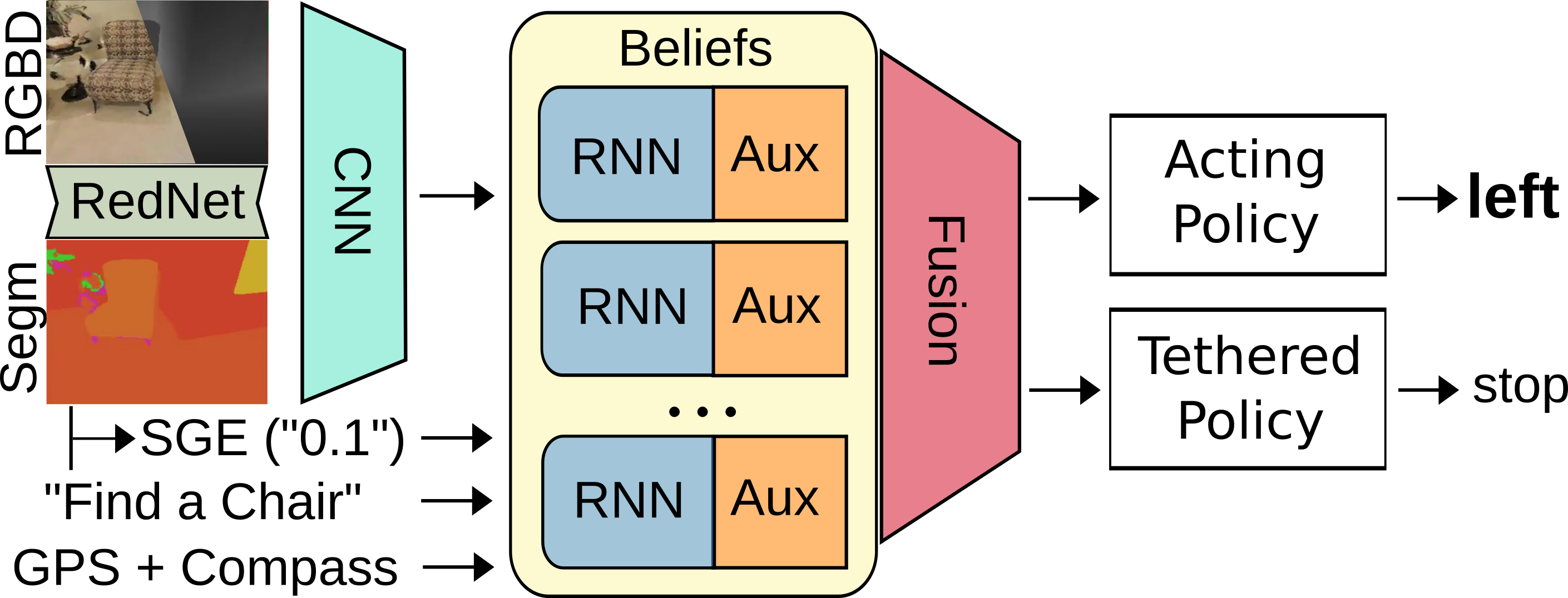 Our agent must navigate to a goal instance from RGBD-Input and a GPS-Compass sensor. Building on Ye et al, 2020, we introduce new auxiliary tasks, a semantic segmentation as visual input, a Semantic Goal Exists feature which describes the fraction of the frame occupied by the goal class, and a method for tethering secondary policies that learns from its own reward signal with off-policy updates. We encourage the acting policy to explore and the tethered policy to perform efficient ObjectNav.
Our agent must navigate to a goal instance from RGBD-Input and a GPS-Compass sensor. Building on Ye et al, 2020, we introduce new auxiliary tasks, a semantic segmentation as visual input, a Semantic Goal Exists feature which describes the fraction of the frame occupied by the goal class, and a method for tethering secondary policies that learns from its own reward signal with off-policy updates. We encourage the acting policy to explore and the tethered policy to perform efficient ObjectNav.
Qualitative Examples
We provide selected videos of various agents on the validation split, highlighting pieces of the analysis (failure modes and agent instability). The videos show, from left to right, RGB, Depth, Semantic Input (either ground truth or RedNet segmentations), and the top-down map (the agent does not receive a top-down map). The top down map shows goals as red squares and valid success zones in pink. The annotations at the top left of each video show the coverage and the SGE fed into the agent. Unless otherwise indicated, the videos use GT segmentation.
Selected Successes from 4-Action, 6-Action, and 6-Action + Tether
All of the following have a cushion goal. 4-Action: SPL 0.66.
6-Action: SPL 0.57.
6-Action + Tether: SPL 0.82.
4-Action: SPL 0.08.
6-Action: SPL 0.06
6-Action + Tether: SPL 0.60
Failure Modes
We present samples of failure modes noted in the behavioral study for the base agent.
Plateau (Spawn)
Plateau
Last Mile
Loop
Open
Dataset Bug: Bed (Goal) is in segmentation
Detection: Agent glimpses goal at ~0:15 - 0:20.
Commitment: Agent ignores
Explore
Quit (Tether Failure)
Unstable Behavior on Zero-Shot Transfer to RedNet Segmentation
4-Action
6-Action
4-Action (Example 2)
6-Action (Example 2)
Additional Random Successes for 6-Action Base Agent
Goal: Chair
Goal: Chest of Drawers
Goal: Chair
Additional 6-Action Base Episodes with RedNet Segmentation
Goal: Plant
Goal: Picture